Disaster Recovery and Planning concepts

Disaster Recovery and Planning Concepts Introduction
In the current article, I’m introducing Disaster Recovery and planning.
Disaster Recovery and planning concepts (DR) is a critical plan that implements backup services to ensure continuity of business services provided by the data center.
in case of any disaster incident that might occur in the primary data center site. Disasters range from natural catastrophes such as earthquakes to unplanned system crashes.
Minor problems such as system crashes, single physical hardware failures, connectivity disruptions are not considered disasters.
As recovering from failures is not too much costly, while a fire case in a data center is considered a disaster.
Let's define what is considered a disaster:
Disaster Recovery and Planning Cost
If the cost of recovery relative to the cost of damages is very high, the issue is considered a disaster.
An example is a fire case in a data center that damages 10 physical servers. The cost of purchasing new servers and implementing them in the data center is very high.
On the other hand, losing one router in a data center is not considered a disaster because of the low price of the new router relative to the solution of recovery.
It is a matter of cost only, and what is considered a disaster to some companies might be a minor loss to another based on their financials and budgets provisioned to IT infrastructure.
Disaster Recovery and Planning Downtime
It is also relative to service and business nature.
Disruption of Email service in a company where its business depends mainly on emails is considered a disaster.
Such companies do not accept email service to be down for a long time because each minute is translated to money and one minute of email disruption may cause the loss of millions of dollars.
Other companies -relative to their business needs- may sustain email service to be down for more than one day without any financial losses, in that case, losing email service is not a disaster, but a service failure.
Disaster Recovery and Planning Recovery Time
If the time required to recover from a failure is long, the case is considered a (disaster).
Generally speaking, but not a rule, losing service for more than 3 days is considered a disaster
(That is the time required to bring the service up not time passed since it had gone down).
In certain cases, one hour recovery time is enough to shift a case from Service Failure zone to Disaster zone. Again, it is a matter of business nature.
A look at the following table explains the differences between three common types of problems: Disaster, Service Disruption (failure), and Minor Problem, accompanied by business continuity solutions.

Differences between three common types of problems: Disaster, Service Disruption (failure), and Minor Problem, accompanied with business continuity solutions.
Disaster Recovery planning:
Planning Disaster Recovery is a critical task and is the foundation of a successful business.
Infrastructure admins must plan the Disaster Recovery Site (DR Site) during the phase of planning infrastructure and datacenters not after.
The procedure is not complementary to main site planning but parallel to it. Adding DR Sites to the existing datacenter primary site is a complex and costly task.
Here are 4 steps to follow when you plan DR Site during the Primary Site planning phase.
Step 1: Define Required Services and Solution Plans:
I recommend you create the following table during the planning phase of your primary / main data center based on your organization’s business nature and budget provisioned to IT Dept.
Consider two scales for both Downtime Cost and Replication Bandwidth, which is based on your business. I put some examples in the table for better understanding.
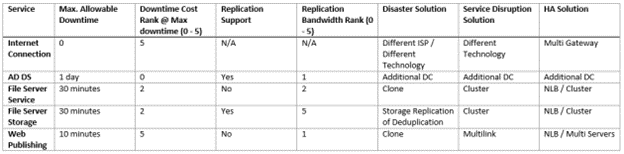
Downtime Cost and Replication Bandwidth examples.
I put some examples in the table for better understanding.
- Service: List of all services that will be introduced by the datacenter like Email, Web Publishing, etc.
- Max. Allowable Downtime: Discussing each service with decision-makers and based on organization security policy aside from admin experience, define the maximum allowable time for a service to be down. This will define what solution is available to overcome any failures that occur for the service.
- Downtime Cost Rank @ Max Downtime: Based on the scale you selected before; rank cost due to any down of the service, hence with aid of table 1, you can clearly categorize if it's Disaster, Service Disruption, or Minor Problem. In the example I used a scale from 0 to 5, 0 is minimum and 5 is maximum.
- Replication Support: Define if the service comes with built-in replication support, such as AD DS or will need an external replication solution that must be taken into consideration from both cost and technology perspectives.
- Replication Bandwidth Rank: Based on the scale you selected for bandwidth, give replication a rank. This will help you plan your connectivity needs and is directly affecting setup costs.
- Disaster Solution: Define the best solution to be implemented in your DR Site for a particular service.
- Actually, this will show up clearly to your mind just you complete all fields because you already noted down all factors that affect your selection.
- Service Disruption Solution: Define a solution for service disruption,
- the solution is not targeted to be located in the DR Site but in the primary site, so it is not based on Replication Bandwidth Rank.
- Replication will depend only on connectivity implemented in Primary Sites.
- HA Solution: Define the best solution for high availability. This solution is a mix of DR and Service Disruption solutions.
- You don’t need your service to be down in case of main site failure either due to natural catastrophe or internet link disconnection. HA aims to keep service up regardless of a failed component or its physical location.
Step 2: Plan Primary Sites Infrastructure:
Based on Step 1, plan Primary sites that required logical and physical infrastructure and define resources.
It is very important to estimate the average workload by each service.
You can use the following table to note down workloads.
 table to note down workloads.
table to note down workloads.
Step 3: Plan DR Site logical infrastructure:
Based on information defined in Step 1 start planning logical infrastructure for the DR Site, employing suggested solutions defined in “Disaster Solution”, and consider use DR Site for HA under certain conditions.
Step 4: Define DR Site Hardware Requirements:
Based on estimated average workloads from Step 2, Maximum Allowable Downtime information from Step 1, and DR Site Logical infrastructure planned in Step 3; define hardware required to build DR Site.
In this phase try to minimize required hardware as much as possible, to decrease initial setup cost, maintenance efforts, and complexity.
You can benefit from old hardware marked for upgrades like Servers that have to be replaced and outdated Router or Switches.
Keep in mind that DR Site is very critical, and at the same time it may not carry real workloads over its life span.
Frankly, if the infrastructure administrator plans Primary Site perfectly, DR Site will not be active except in case of a natural catastrophe or during scheduled simulations.
Be very careful and invest enough time planning the DR site.
The steps are summarized in the flowchart.
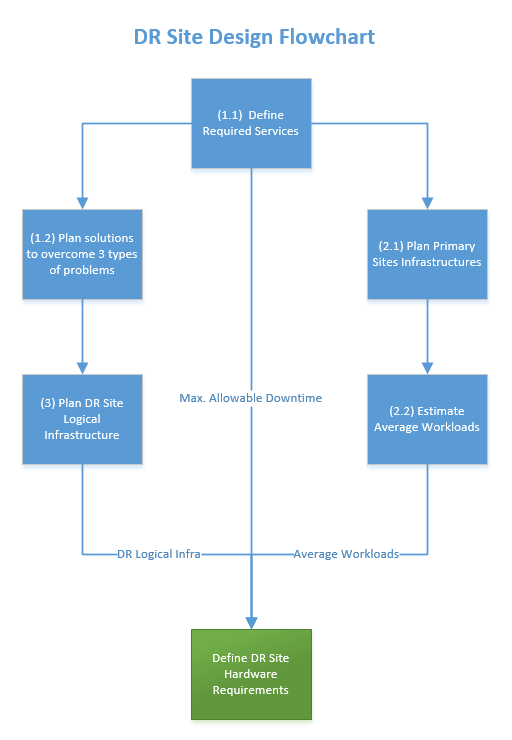
Disaster Recovery and Planning site flowchart
Consider the following while planning DR Site:
- Site is recommended to exist in different geographical locations than Primary sites, like different cities or even different countries to overcome problems such as natural catastrophes, regional electricity shutdown, ISP service failures, etc.
- Use different connectivity technologies from different ISPs. For example, mix leased lines with microwave technology for connectivity links.
- At least, two connectivity lines must be implemented in the DR Site.
- It is highly recommended to employ an on-site administrator for the DR Site. He will be responsible for regular hardware and software maintenance, ensuring service states, monitoring replication, and backup status, performing scheduled disaster simulations, reporting performance counters to IT Directors in order to validate SLAs and QoS.
And
- DR Site must be physically highly secured from unauthorized access on both digital and physical levels, as it will contain a replica of the organization’s primary site information. In fact, it must be secured more than the primary site.
- Data, Connections, and data links between primary and DR sites have to be highly secured from threats and breaches by technologies such as PKI, SSL, IPsec VPNs, or secured MPLS with good encryption algorithms.
- An unscheduled random disaster simulation has to be performed by IT Directors and Higher Lever Infrastructure Administrators to ensure stability and availability of the DR Site.
- Upgrade plans must be available for the DR site. Plans should employ solutions for upgrades with zero downtime for the DR Site.
- Plan your DR Site infrastructure near the edge of hardware capabilities to decrease setup cost, while not sacrificing availability and performance.
You can also learn more about Digital Transformation in business like:


